
第2回:FileMaker とAWS Bedrock|RAGの仕組みをわかりやすく解説!AI連携の裏側とは?
前回は、FileMaker とAmazonの生成AIサービス「AWS Bedrock」を連携させることで、あなたの業務がどのように進化するのか、5つの未来像をご紹介しました。
- 未来1:セマンティック検索で“探す時間”がゼロに
- 未来2:問い合わせメールをAIが半自動送信!対応品質も向上
- 未来3:議事録や報告書をAIが一瞬で要約
- 未来4:蓄積されたデータが「勝ちパターン」を導き出す
- 未来5:AIが操作マニュアルになる「社内AIチャットボット」
「そんな便利なこと、本当にできるの?」 「でも、一体どうやって実現するの?」
そう思われた方も多いのではないでしょうか。
📍前回の記事はコチラから
今回の第2回では、その「仕組み」の裏側を、少しだけ技術的な視点も交えながら、分かりやすく解説していきます。
目次
そもそも「AWS Bedrock」って何?

簡単に言うと、AWS Bedrockは「色々な会社のAIを手軽に、安全に使えるようにする Amazon のサービス」です。
- 色々なAIを選べる:Amazon自身のAI(Titan)だけでなく、AI業界で有名なAnthropic社の「Claude」など、複数の高性能AIモデルを簡単に利用できます。
- 導入コストを大幅に削減:従来のAI導入では、高価な専用サーバーの構築・管理や、有償のAPI利用が必要で、コストが課題でした。Bedrockはサーバーの管理が不要なため、インフラコストを大幅に抑えることが可能です。
- スピーディな実装を実現:複雑なサーバー構築や運用をAWSに任せられるため、開発者は「AIをどう活用するか」という本質的な部分に集中できます。これにより、開発から実装までが迅速になり、AIによる効果をいち早く実感しやすくなります。
- データは安全:送信したデータ(社内機密など)はAIの学習には使われないため、セキュリティ面でも安心です。
今回の連携のキホン:「RAG」とは?
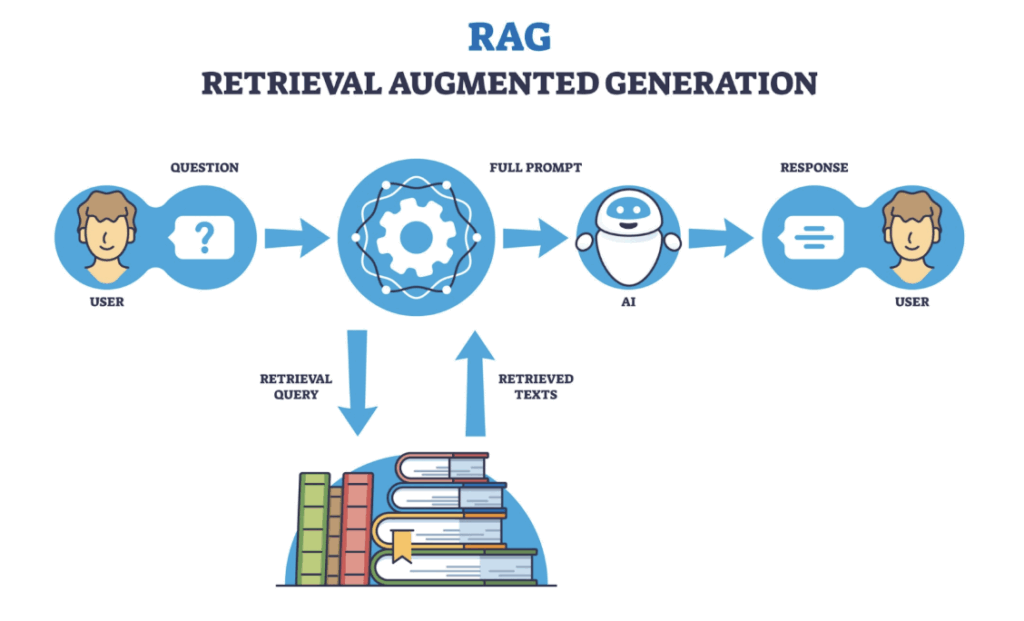
前回ご紹介した「セマンティック検索」や「社内AIチャットボット」を実現する技術の核となるのが RAG(Retrieval Augmented Generation) です。
RAGとは、AIが回答を生成(Generation)する際に、あらかじめ用意された社内データ(ナレッジベース)から関連情報を検索(Retrieval)し、その情報を補強材料として(Augmented)回答を生成する技術のことです。
RAGの流れ(例:社内マニュアル検索)
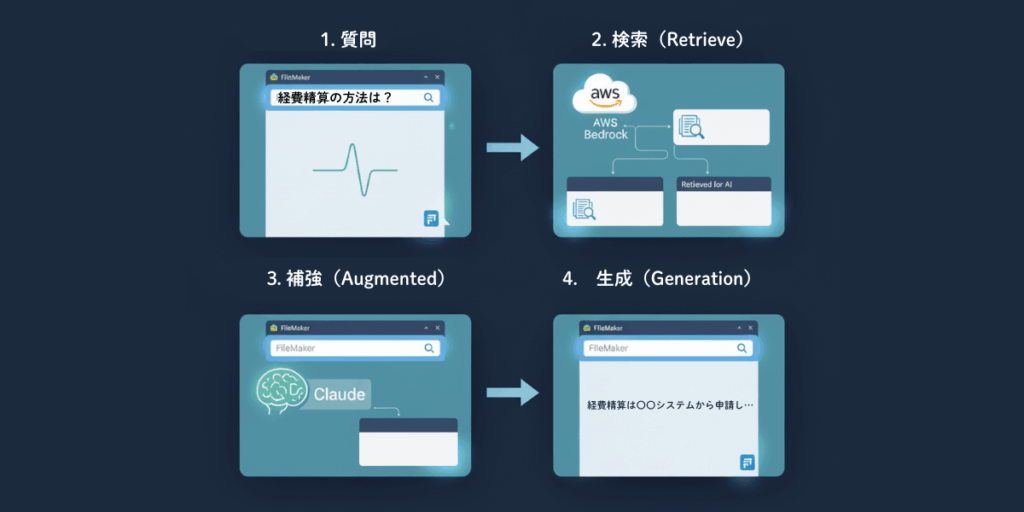
- 質問: ユーザーがFileMaker に「経費精算の方法は?」と質問します。
- 検索(Retrieve):AWS Bedrockが社内マニュアルの中から関連情報を検索
- 補強(Augmented):見つけた情報と質問をセットにしてAIモデル(例:Claude)に渡す。
- 生成(Generation):AIが「経費精算は〇〇システムから申請し…」といった回答を生成。
これにより、AIがインターネット上の不確かな情報に基づいて答えてしまうのを防ぎ、自社の与えたデータに基づいた正確な回答を得られるのです。
FileMaker とAWS Bedrock連携の全体像

では、FileMaker からこのRAGの仕組みを利用するために、どのようなシステム構成になっているのでしょうか?サポータス社内で実際に稼働してるシステムから全体像を見てみましょう。
- FileMaker(業務アプリ):ユーザーが質問を入力するインターフェース。APIリクエストを送信。
- API Gateway:FileMakerからのリクエストを受け付け、Lambda関数を起動。IAM認証で不正アクセスを防止。
- Lambda(メイン処理):FileMaker からの指示を受け、Bedrockを呼び出す。
- Bedrock ナレッジベース:
- RetrieveAndGenerate API: Lambdaから呼び出され、検索と回答生成を一括で実行。
- ベクトルストア (Aurora DB): S3などから取り込んだ社内データ(マニュアル、議事録など)をベクトル化して保存。
- 生成モデル (例: Claude 3 Haiku): 検索結果を基に最終的な回答を生成。
データの流れ(RAGの場合):
- FileMaker (業務アプリ)が質問をAPI Gatewayに送信。
- API GatewayがIAM署名を検証し、Lambdaを呼び出す。
- LambdaがBedrockのRetrieveAndGenerate APIを呼び出す。
- BedrockがAurora DBから関連情報を検索し、Claude 3 Haikuで回答を生成する。
- BedrockがLambdaに回答と引用元を返す。
- LambdaがAPI Gatewayに回答を返す。
- API GatewayがFileMaker(業務アプリ)に応答を返す。
- FileMaker (業務アプリ)が回答を表示する。
少し複雑に見えるかもしれませんが、各サービスが明確に役割分担することで、安全かつ効率的なAI連携が実現しています。
次回予告:コストの話と最初のステップ
今回は、FileMaker とAWS Bedrock連携の「仕組み」の裏側を解説しました。
RAGという技術と、それを支えるAWSの各サービスの役割が、少しでもイメージできたでしょうか?
「でも、これだけ色々使うとなると、コストが高いんじゃないの?」
「具体的に、何から始めればいいの?」
そんな疑問にお答えするため、次回【第3回】では、
「気になるコストは?AWS Bedrock連携を安価に始める方法」をテーマに、
コストの考え方と導入の最初のステップを解説します。
どうぞお楽しみに!
🔗 関連リンク
🤖AWS公式サイト
L AWSとは?
L RAGとは?
✏️FileMaker とAWS Bedrockに関する記事
L第1回:AWS Bedrock|AI 業務改善でデータが「稼ぐ力」に変わる
🌐 サポータス公式サイト(ソリューション紹介)
L SNS( Twitter | Facebook)
L FileMaker導入事例まとめ




