
「自然言語」と「ベクトルデータ」のちがい

2024年6月に発売された「Claris FileMaker 2024(バージョン21)」ではAIのサポートが拡張され、新たに「セマンティック検索を実行」などの機能が実装されました。
この新しく追加されたスクリプトステップ「セマンティック検索を実行」を使用して文脈を理解した検索をおこなうことができるようになりました。
さっそく試してみたところ、「セマンティック検索を実行」の操作モードに「自然言語」と「ベクトルデータ」があることと、それはクエリオプションで指定すること可能とわかりました。

「ベクトルデータ」については何となく想像がつきます。AIで検索するには検索される内容をベクトルデータ化する必要があり、検索テキストも同様にベクトルデータ化する必要があるからです。
そのため「ベクトルデータ化」を処理するスクリプトステップが用意されています。「対象レコードに埋め込みを挿入」と「埋め込みを挿入」または「GetEmbedding」になります。主に下記で使用します。
- 検索したい文字 : 「埋め込みを挿入」または「GetEmbedding」
- 検索対象 : 「対象レコードに埋め込みを挿入」
※GetEmbedding : オブジェクトデータとしてのみ返す
では、もうひとつの「自然言語」とは何なのでしょうか。
- ベクトルデータ化は必要ないのか
- 検索結果は「ベクトルデータ」と異なるのか
- 結局どちらを使用すればいいのか
という疑問がでてきましたのでみていきたいと思います。
■サンプルApp ~セマンティック検索~
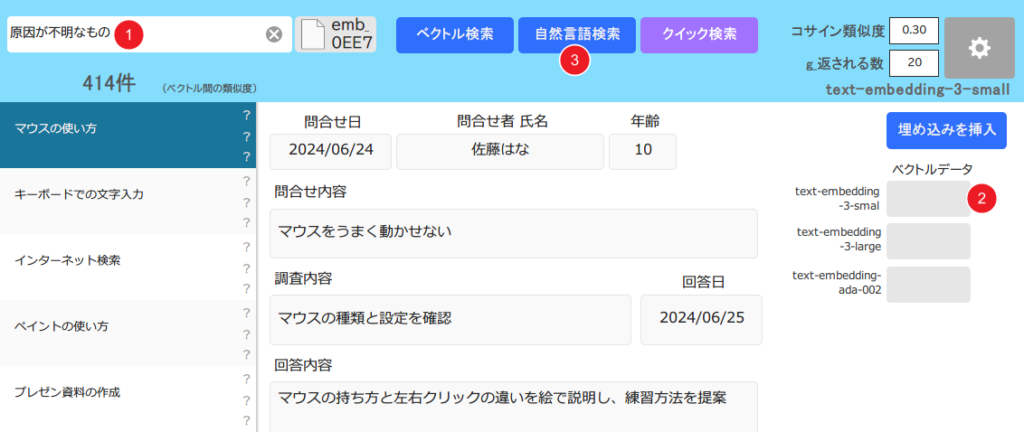
今回検証に用いたサンプルAppは、「パソコン修理サービス」の問い合わせ履歴データ管理です。
従来の検索は単純なキーワードによるマッチングでしたが、「セマンティック検索」は FileMaker 2024 から導入された「テキストの意味や文脈を理解して検索を行う」高度な検索方法です。
ベクトルデータ化は必要ないのか
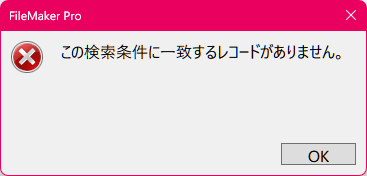
ヘルプをみると、「フィールドの内容は埋め込みベクトルである必要があります。」とあるので必要なのでしょうが、念のため検証してみたいと思います。

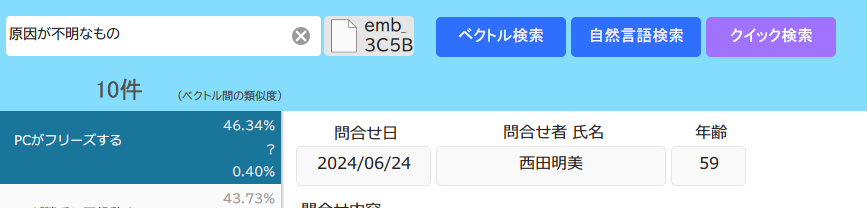
- 検索文字列
- 検索対象のベクトルデータは空(「対象レコードに埋め込みを挿入」をしていない)
- セマンティック検索で「自然言語」を指定して検索を実行

※モデルはOpen AIの「text-embedding-small」を使用
実行結果は下記となりました。
検索結果は「ベクトルデータ」と異なるのか
先ほどのサンプルアプリで「対象レコードに埋め込みを挿入」を実行してベクトルデータを生成しておきます。

セマンティック検索で「ベクトルデータ」を指定するスクリプトは下記になります。

▼「自然言語」での結果
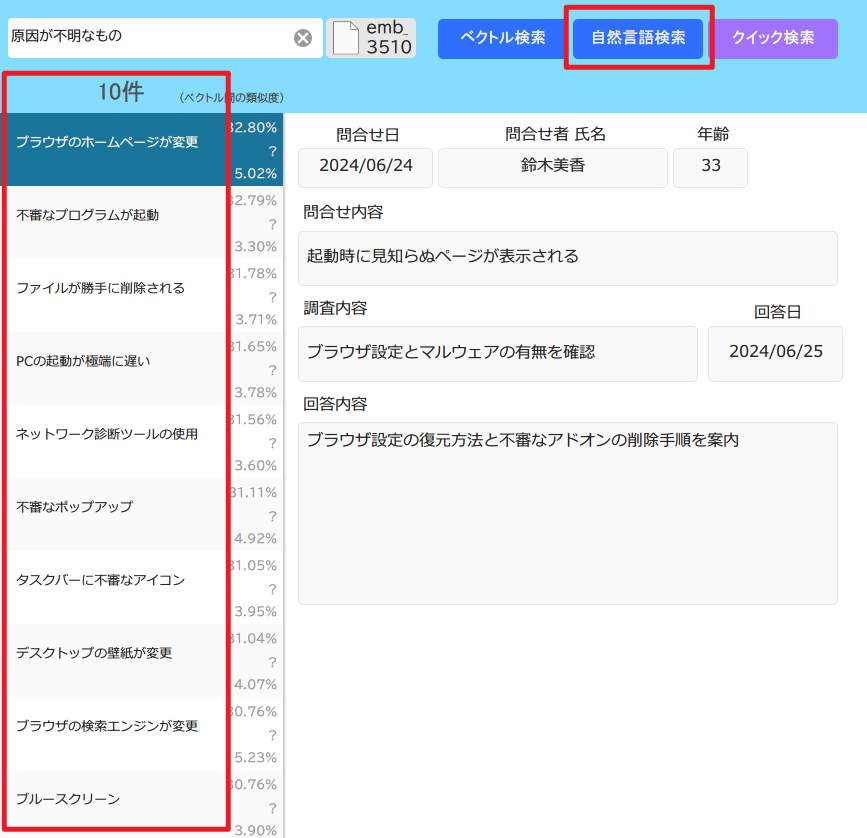
▼「ベクトルデータ」での結果
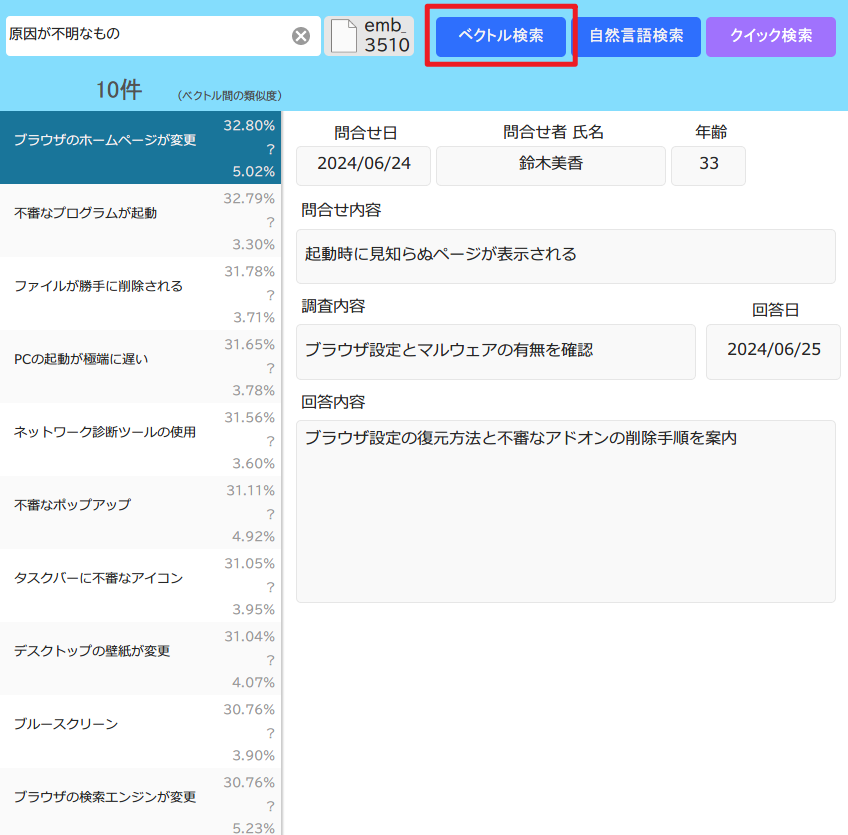
両者の検索結果については違いがありませんでした。
▼検索文字を「故障が原因と思われるもの」にした場合の両者の検索結果

こちらも両者の検索結果については違いがありませんでした。
結局どちらを使用すればいいのか
「ベクトルデータ」による検索の場合、事前に検索テキストの内容をベクトルデータ化しておく(*1)必要がありました。そのため頻繁に特定の検索を利用する場合、その内容を保存しておくことで効率的な検索(*2)をすることが可能になります。
(下記の例ではグローバルフィールドに結果を保存)
*1

*2

「自然言語」の場合は「セマンティック検索を実行」を処理するたびに検索テキストの内容を、AI側に送信して、ベクトルデータに変換してもらう必要があります。

また、検索テキストの内容のベクトルデータ化する分だけ処理時間が遅くなります。
こうしてみると、どちらの場合でも検索テキストの内容をベクトルデータ化することは必要となります。
ユーザーは検索テキストの内容をいつベクトルデータ化しているかについて意識する必要はないはずです。しかし費用については敏感でしょう。
「AI側に送信してベクトルデータに変換」する作業にはトークンに応じて費用が発生するので、頻繁に利用される検索テキストは保存しておいて再利用すれば費用を抑えられることになります。
最後に
いかがでしょうか。どちらが効率的かは、具体的な利用状況によります。用途や目的に応じて適切な方を選択することが重要です。
今回ふれませんでしたが、ベクトルデータに変換した内容は「テキスト」または「バイナリデータ」として保存可能です。「バイナリデータ」として保存しておくことで容量の節約、検索時間の短縮が可能となりそうです。機会があればブログ記事を作成してみたいと思います。
この記事が参考になれば幸いです。




